许多时候,我们使用Python,并不用写一个程序,一些不复杂的任务,我更喜欢在 IDLE(也就是交互式提示模式)下输入几行代码完成。然而,在这个模式下编辑代码,也有不够便利的地方,最主要的就是,不能用Tab自动补全,不能记忆 上一次输入的命令(没办法,谁让我们在Shell下习惯了呢)。
这时候,我们可以直接使用Python启动脚本,解决这个问题。
启动脚本的程序非常简单,这里不多说明,只给出代码:
import readline import rlcompleter import atexit import os # tab autocomplete readline.parse_and_bind(‘tab: complete’) # history file histfile = os.path.join(os.environ['HOME'], ‘.pythonhistory’) try: readline.read_history_file(histfile) except IOError: pass atexit.register(readline.write_history_file, histfile) del os, histfile, readline, rlcompleter
完成之后,我们把它保存为.pythonstartup,存放在自己的目录下(譬如/home/yurii),再将PYTHONSTARTUP变量指向刚才放的地址,就可以了。最省事的办法是在bashrc中添加这样一行:
export PYTHONSTARTUP=/home/yurii/.pythonstartup
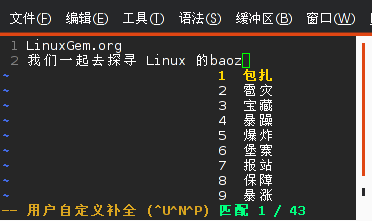
这样,不但增加了tab的自动补全功能,而且重新启动IDLE时,通过上下键,还能翻到上次输入的命令,非常方便。